Hello guys in this article i’m going to show you How to scrape words from website’s & social media’s
Requirements:
- Linux
- internet
- Firefox webdriver
How to install firefox webdriver?
https://github.com/mozilla/geckodriver/releases


chmod +x geckodriver

sudo mv geckodriver /usr/local/bin
Yes now the geckodriver installation was completed.
How to make password list with words-scraper?
git clone https://github.com/dariusztytko/words-scraper.git

Step 2:
Now we have words-scraper folder on our directory. open that folder using this below command.
cd words-scraper
After open the folder we are going to install the requirements of words-scraper tool so type this below command.
sudo pip3 install -r requirements.txt


Step 3:
Now we need to give the permission of read & write and execute the words-scraper by using following command.
chmod +x words-scraper.py
Step 3:
After that you need to run the following order to run the words-scraper
python2 words-scraper.py
This above command will show all attribute explanation and how to use this tool.

Step 4:
Now scrape words from your target website page so run the following command.
python3 words-scraper.py -o triplezero.txt ( you target website name with protocols)
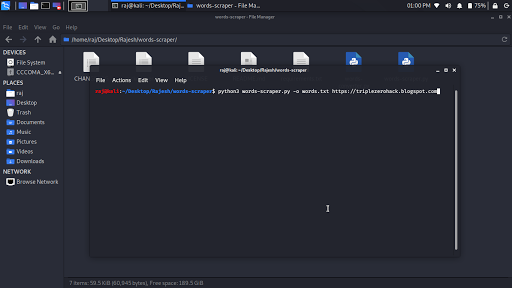
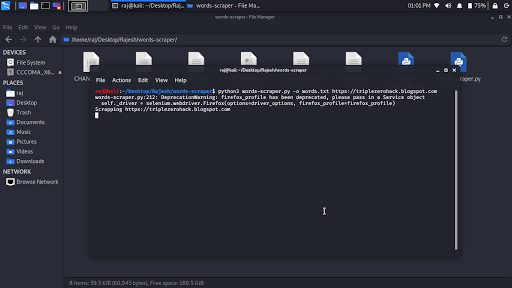
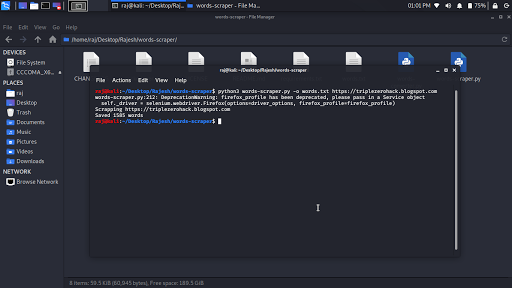
Scraping words from the target’s pages:
python3 words-scraper.py -o words.txt https://www.example.com https://blog.example.com
Such generated words list can be used to perform online brute-force attack or for cracking password hashes:
hashcat -m 0 hashes.txt words.txt
Use –depth option to scrape words from the linked pages as well. Optional –show-gui switch may be used to track the progress and make a quick view of the page:
python3 words-scraper.py -o words.txt –depth 1 –show-gui https://www.example.com
Generated words list can be expanded by using words-converter.py script. This script removes special chars and accents. An example Polish word źdźbło! will be transformed into the following words:
źdźbło!
zdzblo!
źdźbło
zdzblo
cat words.txt | python3 words-converter.py | sort -u > words2.txt
Scraping words from the target’s Twitter
Twitter page is dynamically loaded while scrolling. Use –max-scrolls option to scrape words:
python3 words-scraper.py -o words.txt –max-scrolls 300 –show-gui https://twitter.com/example.com
ssh -D 1080 -Nf {USER-HERE}@{IP-HERE} >/dev/null 2>& $ python3 words-scraper.py -o words.txt –socks-proxy 127.0.0.1:1080 https://www.example.com
إرسال تعليق